 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interspeech 2025 Speech Accessibility Project Challenge
Jul 29, 2025While the last decade has witnessed significant advancements in Automatic Speech Recognition (ASR) systems, performance of these systems for individuals with speech disabilities remains inadequate, partly due to limited public training data. To bridge this gap, the 2025 Interspeech Speech Accessibility Project (SAP) Challenge was launched, utilizing over 400 hours of SAP data collected and transcribed from more than 500 individuals with diverse speech disabilities. Hosted on EvalAI and leveraging the remote evaluation pipeline, the SAP Challenge evaluates submissions based on Word Error Rate and Semantic Score. Consequently, 12 out of 22 valid teams outperformed the whisper-large-v2 baseline in terms of WER, while 17 teams surpassed the baseline on SemScore. Notably, the top team achieved the lowest WER of 8.11\%, and the highest SemScore of 88.44\% at the same time, setting new benchmarks for future ASR systems in recognizing impaired speech.
Voice Quality Dimensions as Interpretable Primitives for Speaking Style for Atypical Speech and Affect
May 27, 2025



Perceptual voice quality dimensions describe key characteristics of atypical speech and other speech modulations. Here we develop and evaluate voice quality models for seven voice and speech dimensions (intelligibility, imprecise consonants, harsh voice, naturalness, monoloudness, monopitch, and breathiness). Probes were trained on the public Speech Accessibility (SAP) project dataset with 11,184 samples from 434 speakers, using embeddings from frozen pre-trained models as features. We found that our probes had both strong performance and strong generalization across speech elicitation categories in the SAP dataset. We further validated zero-shot performance on additional datasets, encompassing unseen languages and tasks: Italian atypical speech, English atypical speech, and affective speech. The strong zero-shot performance and the interpretability of results across an array of evaluations suggests the utility of using voice quality dimensions in speaking style-related tasks.
Affect Models Have Weak Generalizability to Atypical Speech
Apr 22, 2025Speech and voice conditions can alter the acoustic properties of speech, which could impact the performance of paralinguistic models for affect for people with atypical speech. We evaluate publicly available models for recognizing categorical and dimensional affect from speech on a dataset of atypical speech, comparing results to datasets of typical speech. We investigate three dimensions of speech atypicality: intelligibility, which is related to pronounciation; monopitch, which is related to prosody, and harshness, which is related to voice quality. We look at (1) distributional trends of categorical affect predictions within the dataset, (2) distributional comparisons of categorical affect predictions to similar datasets of typical speech, and (3) correlation strengths between text and speech predictions for spontaneous speech for valence and arousal. We find that the output of affect models is significantly impacted by the presence and degree of speech atypicalities. For instance, the percentage of speech predicted as sad is significantly higher for all types and grades of atypical speech when compared to similar typical speech datasets. In a preliminary investigation on improving robustness for atypical speech, we find that fine-tuning models on pseudo-labeled atypical speech data improves performance on atypical speech without impacting performance on typical speech. Our results emphasize the need for broader training and evaluation datasets for speech emotion models, and for modeling approaches that are robust to voice and speech differences.
Hypernetworks for Personalizing ASR to Atypical Speech
Jun 07, 2024Parameter-efficient fine-tuning (PEFT) for personalizing automatic speech recognition (ASR) has recently shown promise for adapting general population models to atypical speech. However, these approaches assume a priori knowledge of the atypical speech disorder being adapted for -- the diagnosis of which requires expert knowledge that is not always available. Even given this knowledge, data scarcity and high inter/intra-speaker variability further limit the effectiveness of traditional fine-tuning. To circumvent these challenges, we first identify the minimal set of model parameters required for ASR adaptation. Our analysis of each individual parameter's effect on adaptation performance allows us to reduce Word Error Rate (WER) by half while adapting 0.03% of all weights. Alleviating the need for cohort-specific models, we next propose the novel use of a meta-learned hypernetwork to generate highly individualized, utterance-level adaptations on-the-fly for a diverse set of atypical speech characteristics. Evaluating adaptation at the global, cohort and individual-level, we show that hypernetworks generalize better to out-of-distribution speakers, while maintaining an overall relative WER reduction of 75.2% using 0.1% of the full parameter budget.
Latent Phrase Matching for Dysarthric Speech
Jun 08, 2023



Many consumer speech recognition systems are not tuned for people with speech disabilities, resulting in poor recognition and user experience, especially for severe speech differences. Recent studies have emphasized interest in personalized speech models from people with atypical speech patterns. We propose a query-by-example-based personalized phrase recognition system that is trained using small amounts of speech, is language agnostic, does not assume a traditional pronunciation lexicon, and generalizes well across speech difference severities. On an internal dataset collected from 32 people with dysarthria, this approach works regardless of severity and shows a 60% improvement in recall relative to a commercial speech recognition system. On the public EasyCall dataset of dysarthric speech, our approach improves accuracy by 30.5%. Performance degrades as the number of phrases increases, but consistently outperforms ASR systems when trained with 50 unique phrases.
Nonverbal Sound Detection for Disordered Speech
Feb 15, 2022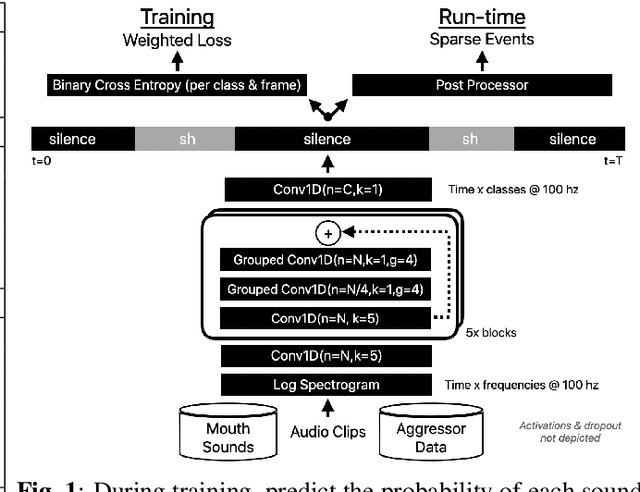
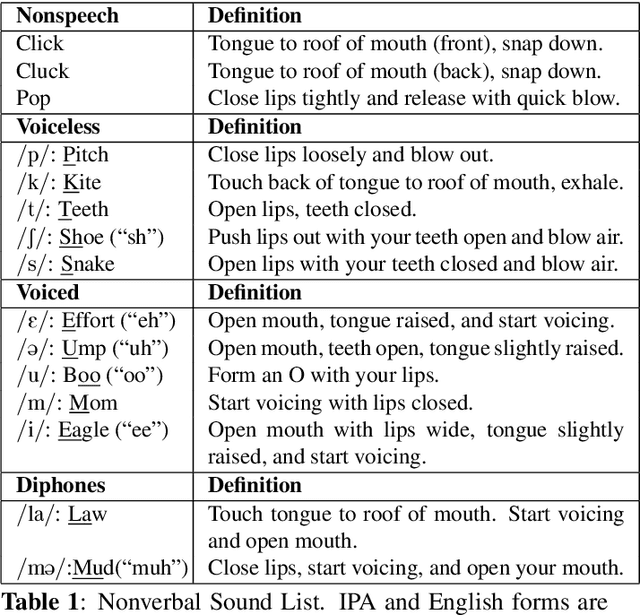
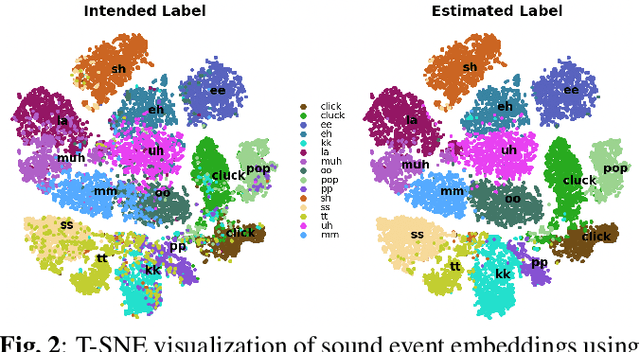
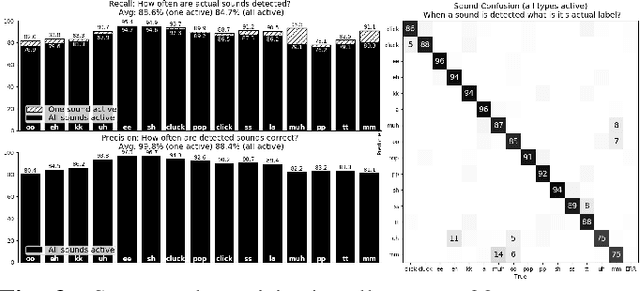
Voice assistants have become an essential tool for people with various disabilities because they enable complex phone- or tablet-based interactions without the need for fine-grained motor control, such as with touchscreens. However, these systems are not tuned for the unique characteristics of individuals with speech disorders, including many of those who have a motor-speech disorder, are deaf or hard of hearing, have a severe stutter, or are minimally verbal. We introduce an alternative voice-based input system which relies on sound event detection using fifteen nonverbal mouth sounds like "pop," "click," or "eh." This system was designed to work regardless of ones' speech abilities and allows full access to existing technology. In this paper, we describe the design of a dataset, model considerations for real-world deployment, and efforts towards model personalization. Our fully-supervised model achieves segment-level precision and recall of 88.6% and 88.4% on an internal dataset of 710 adults, while achieving 0.31 false positives per hour on aggressors such as speech. Five-shot personalization enables satisfactory performance in 84.5% of cases where the generic model fails.
Analysis and Tuning of a Voice Assistant System for Dysfluent Speech
Jun 18, 2021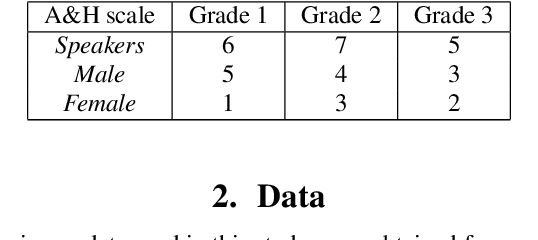
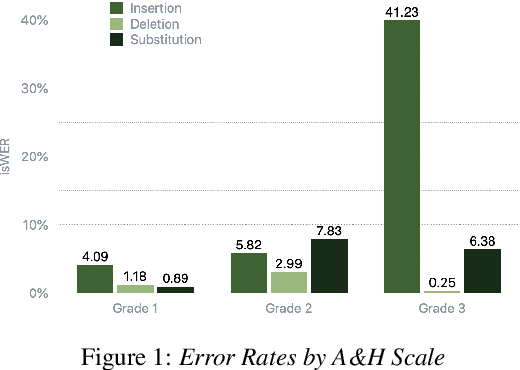
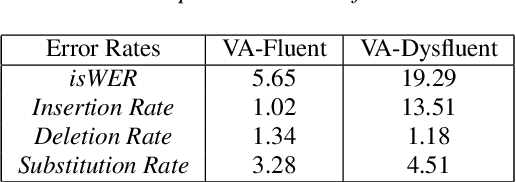
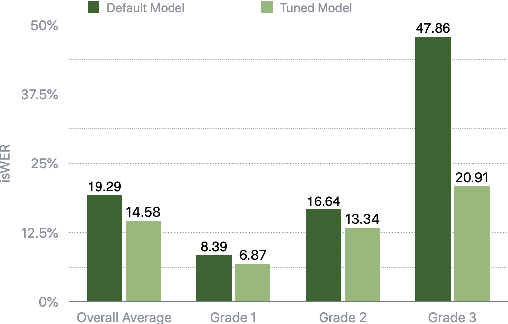
Dysfluencies and variations in speech pronunciation can severely degrade speech recognition performance, and for many individuals with moderate-to-severe speech disorders, voice operated systems do not work. Current speech recognition systems are trained primarily with data from fluent speakers and as a consequence do not generalize well to speech with dysfluencies such as sound or word repetitions, sound prolongations, or audible blocks. The focus of this work is on quantitative analysis of a consumer speech recognition system on individuals who stutter and production-oriented approaches for improving performance for common voice assistant tasks (i.e., "what is the weather?"). At baseline, this system introduces a significant number of insertion and substitution errors resulting in intended speech Word Error Rates (isWER) that are 13.64\% worse (absolute) for individuals with fluency disorders. We show that by simply tuning the decoding parameters in an existing hybrid speech recognition system one can improve isWER by 24\% (relative) for individuals with fluency disorders. Tuning these parameters translates to 3.6\% better domain recognition and 1.7\% better intent recognition relative to the default setup for the 18 study participants across all stuttering severities.
SEP-28k: A Dataset for Stuttering Event Detection From Podcasts With People Who Stutter
Feb 24, 2021
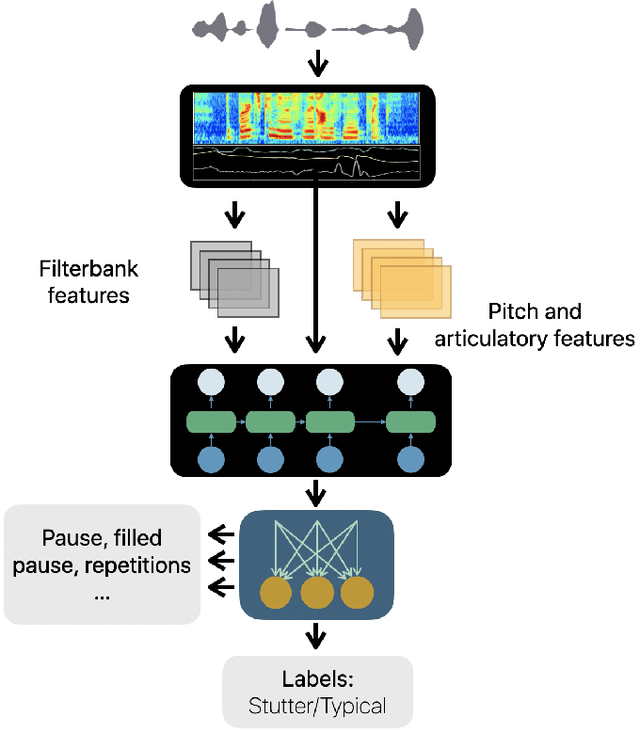
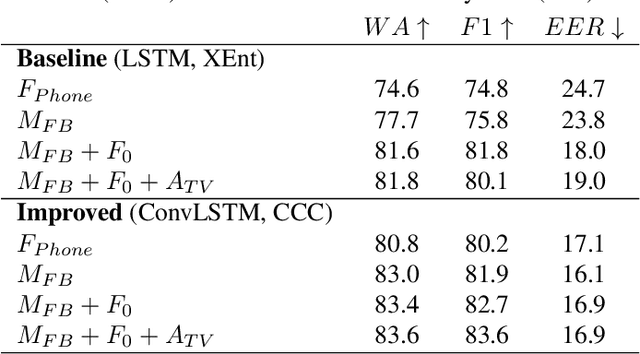
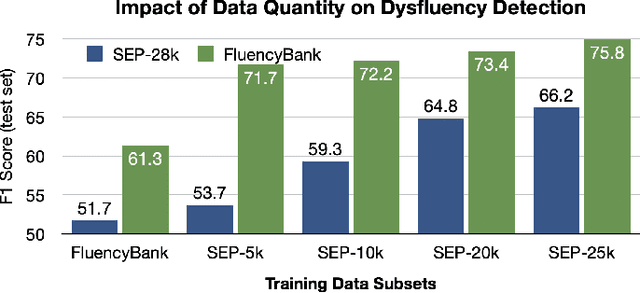
The ability to automatically detect stuttering events in speech could help speech pathologists track an individual's fluency over time or help improve speech recognition systems for people with atypical speech patterns. Despite increasing interest in this area, existing public datasets are too small to build generalizable dysfluency detection systems and lack sufficient annotations. In this work, we introduce Stuttering Events in Podcasts (SEP-28k), a dataset containing over 28k clips labeled with five event types including blocks, prolongations, sound repetitions, word repetitions, and interjections. Audio comes from public podcasts largely consisting of people who stutter interviewing other people who stutter. We benchmark a set of acoustic models on SEP-28k and the public FluencyBank dataset and highlight how simply increasing the amount of training data improves relative detection performance by 28\% and 24\% F1 on each. Annotations from over 32k clips across both datasets will be publicly released.
Audio- and Gaze-driven Facial Animation of Codec Avatars
Aug 11, 2020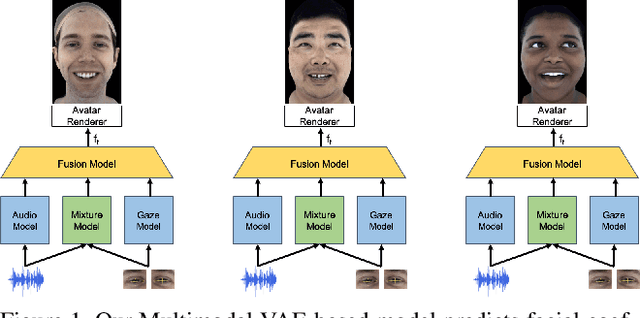
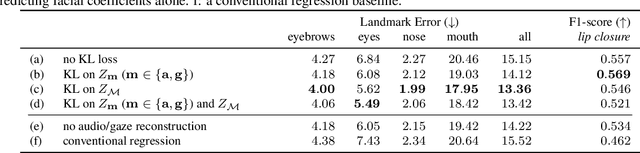
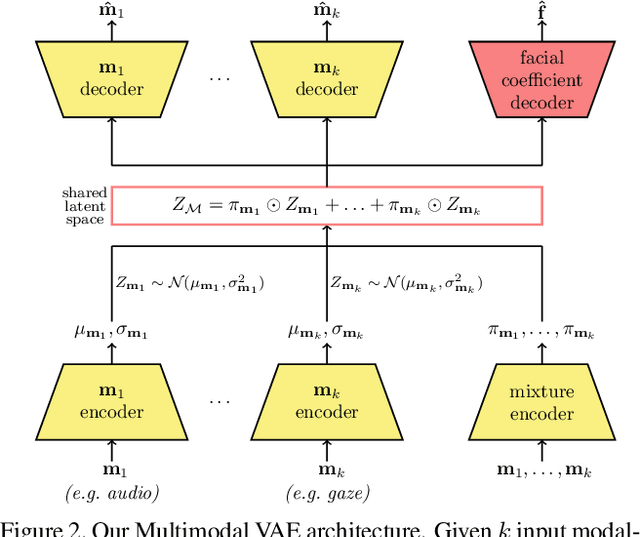
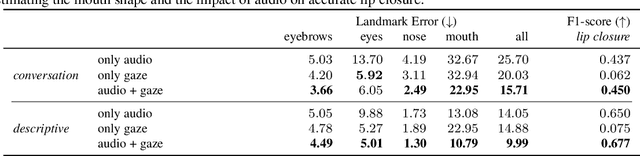
Codec Avatars are a recent class of learned, photorealistic face models that accurately represent the geometry and texture of a person in 3D (i.e., for virtual reality), and are almost indistinguishable from video. In this paper we describe the first approach to animate these parametric models in real-time which could be deployed on commodity virtual reality hardware using audio and/or eye tracking. Our goal is to display expressive conversations between individuals that exhibit important social signals such as laughter and excitement solely from latent cues in our lossy input signals. To this end we collected over 5 hours of high frame rate 3D face scans across three participants including traditional neutral speech as well as expressive and conversational speech. We investigate a multimodal fusion approach that dynamically identifies which sensor encoding should animate which parts of the face at any time. See the supplemental video which demonstrates our ability to generate full face motion far beyond the typically neutral lip articulations seen in competing work: https://research.fb.com/videos/audio-and-gaze-driven-facial-animation-of-codec-avatars/
Temporal Convolutional Networks for Action Segmentation and Detection
Nov 16, 2016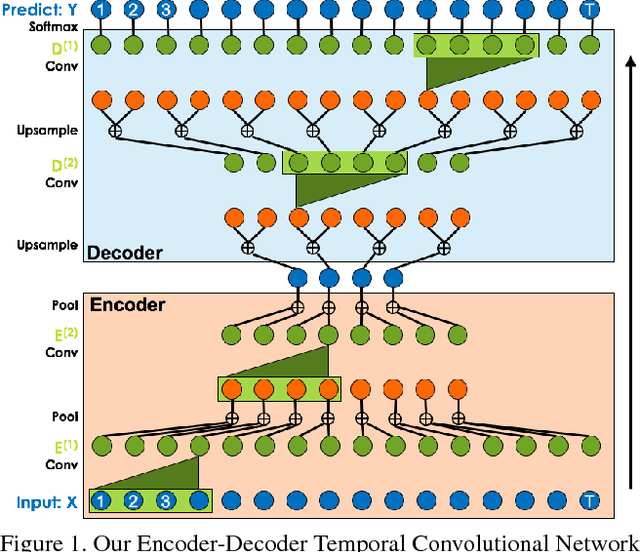
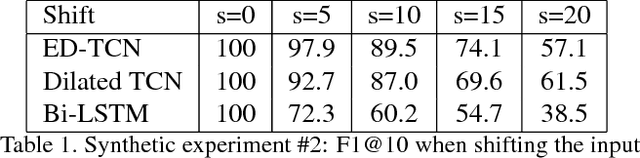
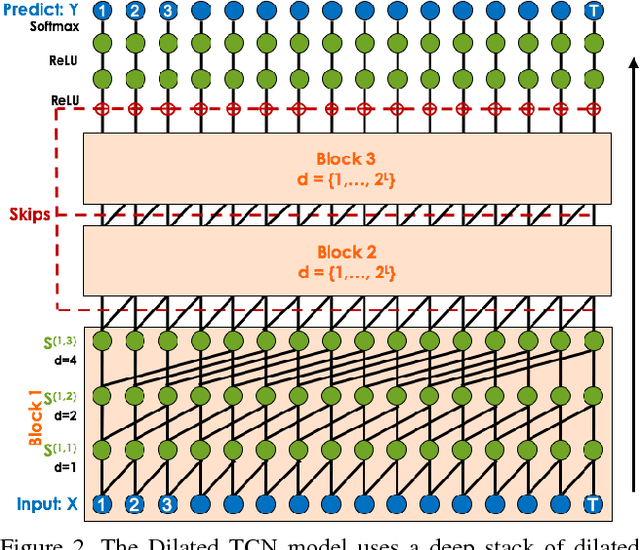
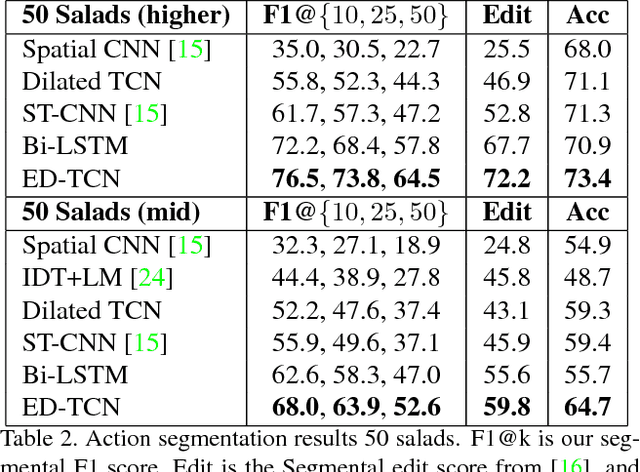
The ability to identify and temporally segment fine-grained human actions throughout a video is crucial for robotics, surveillance, education, and beyond. Typical approaches decouple this problem by first extracting local spatiotemporal features from video frames and then feeding them into a temporal classifier that captures high-level temporal patterns. We introduce a new class of temporal models, which we call Temporal Convolutional Networks (TCNs), that use a hierarchy of temporal convolutions to perform fine-grained action segmentation or detection. Our Encoder-Decoder TCN uses pooling and upsampling to efficiently capture long-range temporal patterns whereas our Dilated TCN uses dilated convolutions. We show that TCNs are capable of capturing action compositions, segment durations, and long-range dependencies, and are over a magnitude faster to train than competing LSTM-based Recurrent Neural Networks. We apply these models to three challenging fine-grained datasets and show large improvements over the state of the art.